Reliable Autonomous Systems
Overview
Welcome to our research dedicated to the study and advancement of autonomous sensing systems. Our work revolves around the core components of Data, Algorithms, and Applications.
Data: At the foundation of our research, we delve into the essence of data - the elemental units. We meticulously design and deploy multi-modality systems to acquire data from both indoor and outdoor environments. This includes the use of multi-modal sensing modalities such as cameras, LiDAR, GPS, IMUs, and environmental sensors, as well as simulations, to ensure comprehensive data collection and sensor fusion.
Algorithms: Our research is deeply rooted in algorithmic innovation. We devote substantial efforts to developing cutting-edge algorithms that play a pivotal role in the efficient and optimal processing of acquired data. Our work spans computer vision, machine learning, sensor fusion, optimization techniques, and robustness measures, ensuring the reliability of our systems.
Applications: Beyond algorithmic refinement and data collection, we aim to bridge theory and practice. Our autonomous systems find practical applications in a variety of domains, spanning from the controlled environments of warehouses to the complexities of outdoor terrains. Applications include autonomous navigation, factory automation, infrastructure sensing, and search and rescue missions, reflecting the versatility and real-world impact of our research.
Publications


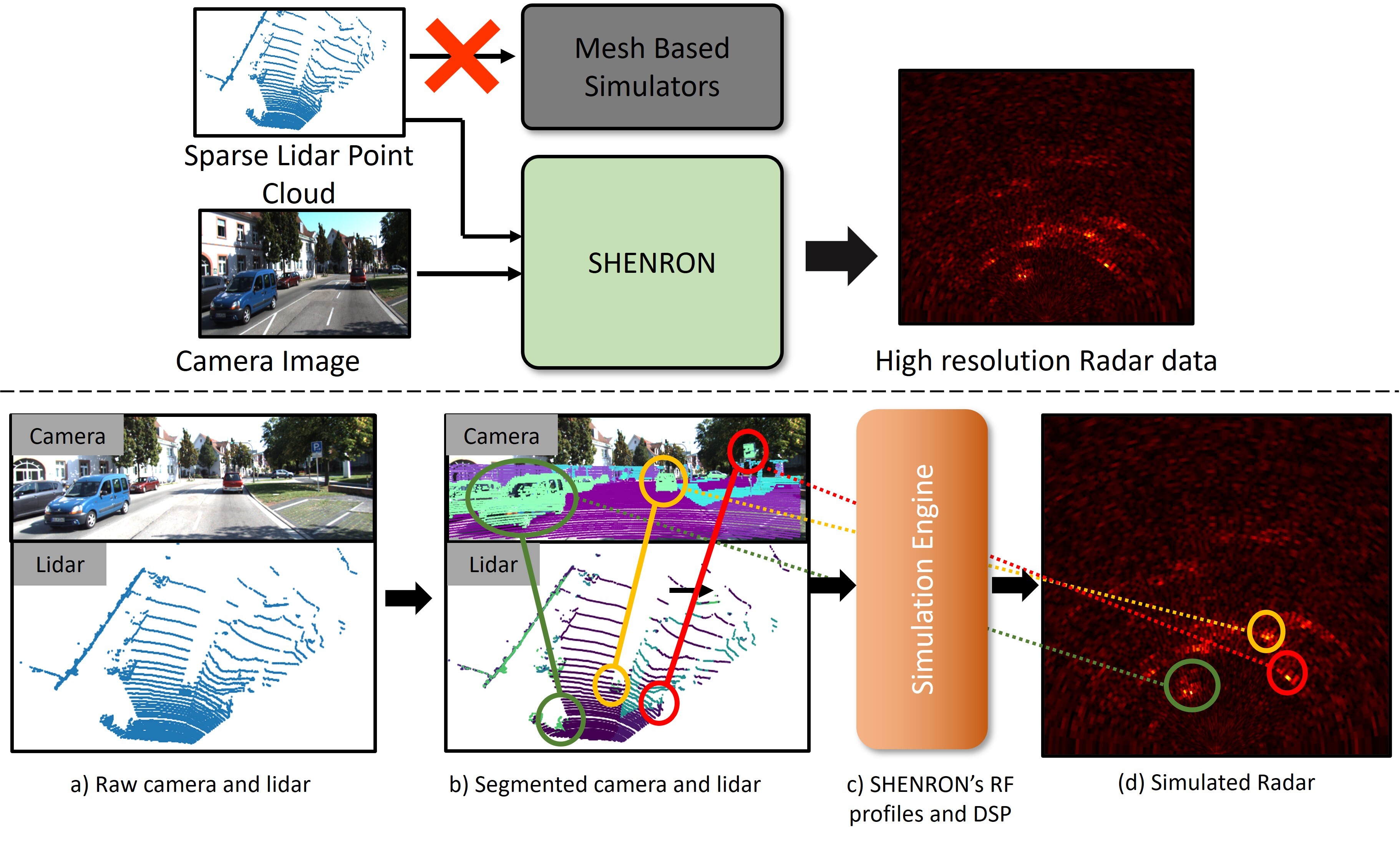

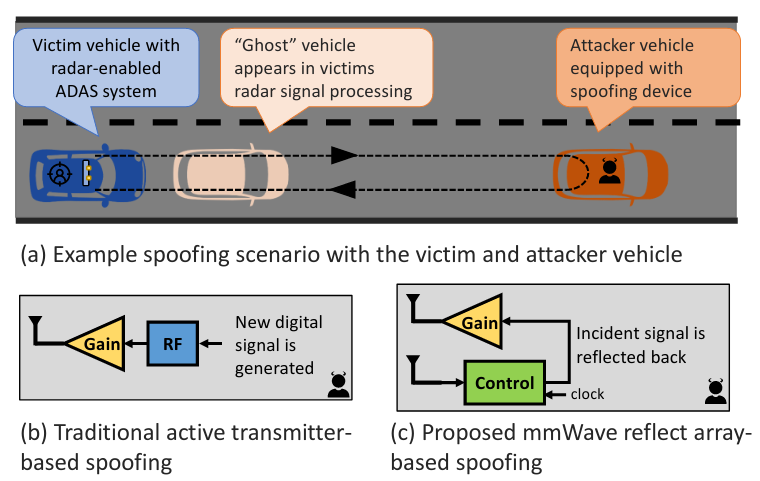
Open Source Code and Datasets
- [ SHENRON - Scalable, High Fidelity and EfficieNt Radar SimulatiON Code ]
- [ Pointillism: Accurate 3D Bounding Box Estimation with Multi-Radars Code ]
- [ Pointillism: Accurate 3D Bounding Box Estimation with Multi-Radars Dataset ]
- [ SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception Code ]
Team



