Modern 5G networks generate gigabytes of DEBUG-level logs per minute across distributed components including CU, DU, RU, and 5GC. These logs are critical for debugging, root cause analysis, and performance monitoring—but are far too large and heterogeneous for direct use with Large Language Models (LLMs). Traditional Retrieval-Augmented Generation (RAG) pipelines struggle at this scale due to embedding overhead, vector search latency, and limited context windows.
We introduce PRISM, a log-aware real-time RAG architecture that enables efficient natural-language question answering over massive 5G log streams. PRISM exploits the structured and repetitive nature of logs by transforming raw entries into template-level representations using n-gram vectorization and dynamic-field masking. Instead of embedding every log line, PRISM builds a compact template library offline and performs high-speed correlation-based pruning online.
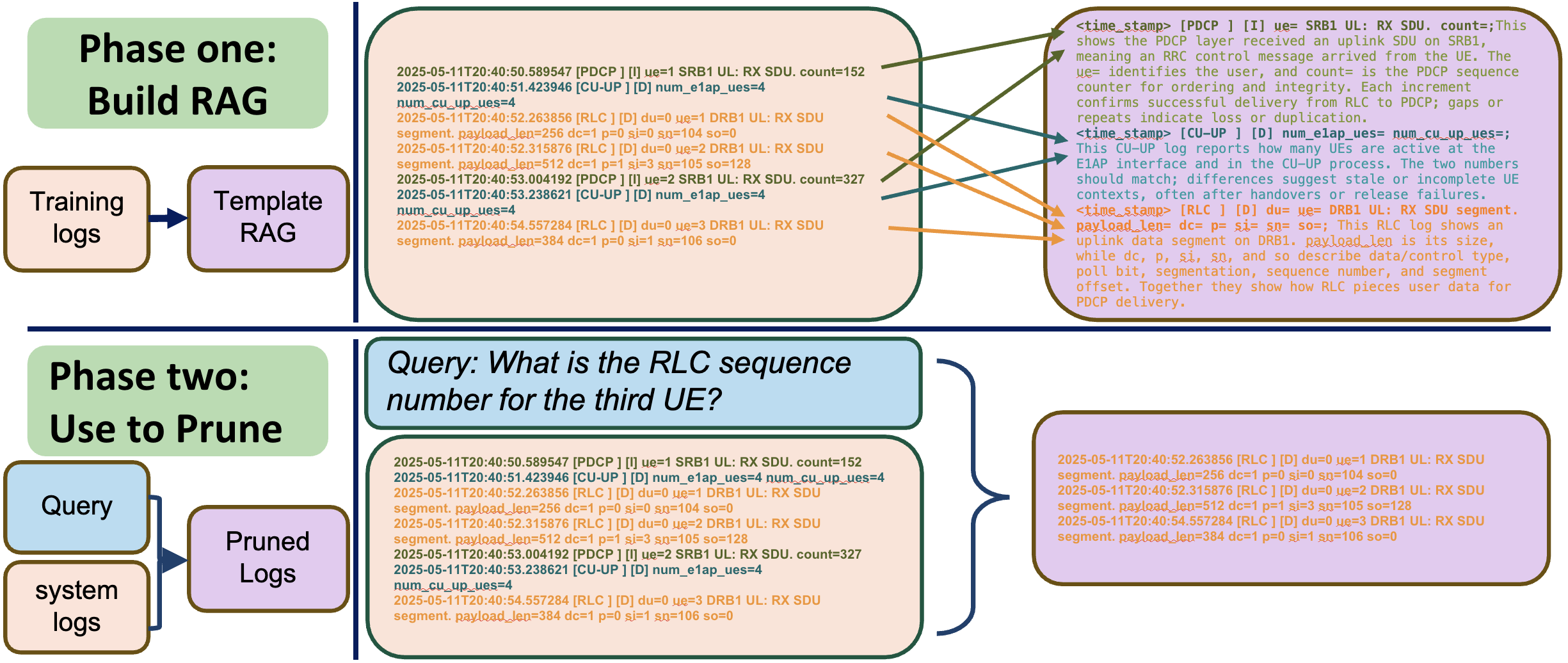
At query time, PRISM retrieves top-k relevant templates using semantic search over augmented template embeddings. These templates are converted into a filter matrix that rapidly matches and selects only the most relevant log entries from the incoming stream. This matrix-based pruning bypasses expensive index lookups and dramatically reduces token count before LLM inference.
We evaluate PRISM on a real-world O-RAN compliant 5G standalone testbed under split-8 and split-7.2 architectures. Across diverse multi-UE, mobility, congestion, and SNR-degradation scenarios, short experiments generate up to 2.8 GB of logs in under two minutes. Using a curated 5G log Q&A dataset, PRISM achieves up to 85% compression while improving answer accuracy and reducing generation latency by more than 3× compared to unpruned baselines.
Our results show that aggressive pruning can improve both speed and accuracy by eliminating noisy context that confuses LLM reasoning. PRISM enables real-time, scalable log interrogation and paves the way for intelligent 5G monitoring, cross-layer diagnosis, and automated network analytics.
|
|